
티스토리 뷰
이전에 강화학습 이론은 우리가 환경에 대한 정보를 안다는 가정을 했었다.
환경이란,
- 상태의 종류 = S
- 행동의 종류 = A
- 행동을 했을 때의 보상 = R
이전에 배웠던 내용들
- 강화학습의 목표는 무엇일까? : 마르코프 결정 과정
- 최적의 행동은 어떻게 찾을까? : 동적계획법 (feat 정책반복)
- 저 효율적으로 최적 행동을 찾을 수는 없을까? : 비동기적 동적계획법
몬테카를로 등장 배경
동적계획법 아래에서 강화학습은
미로(환경)에 대한 정보가 주어지고 그 미로를 통과하기 위한 최적 루트를 찾는 것과 같다.

하지만, 통제된 환경이 아닌 현실세계에서 우리는 위와 같은 정보를 알수가 없다.
그래서 우리는 현재 환경에 대한 정보가 없을때에도
최적의 행동이 무엇인지 찾을 수 있어야 한다.
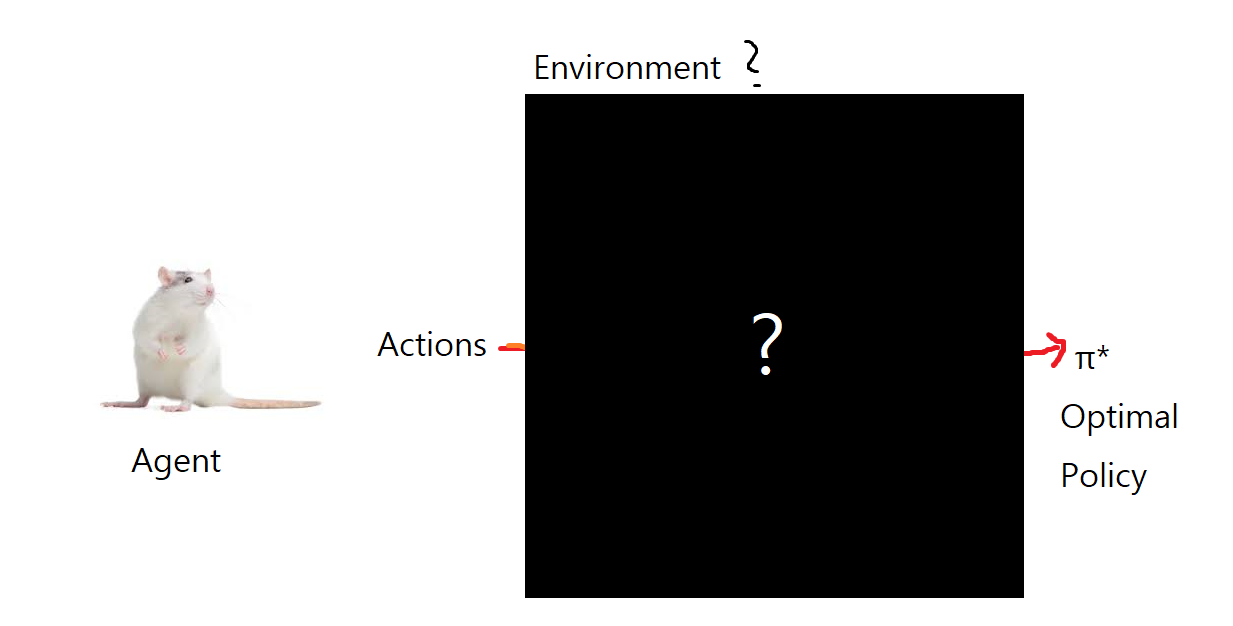
다시한번 강화학습의 목표와 방법을 생각해보자
강화학습
- 강화 학습은 환경에 대한 정보가 없을 때, 다음과 같은 내용을 학습 하게 된다.
- 환경에 대한 이해 없이, 곧바로 최적 행동을 찾는 것
- 환경에 대한 이해 (상태S, 행동A, 보상R)를 통해, 최적 행동을 찾는 것
강화 학습의 패턴 (강화학습은 어떻게 이루어 지는가?)
- 강화학습은 Agent와 Evironment의 상호 작용으로 이루어짐
- Agent는 행동을 수행
- Environment는 행동에 대한 결과 (상태, 보상)를 제공

하지만 강화학습을 할 때, 몇가지 해결해야할 문제가 있다.
- Agent가 행동을 수행할 때 무엇을 기준으로 해야할까? (정책 개선)
- 상태 가치 함수(V)와 행동 가치 함수(Q)를 어떻게 추정 할 수 있을까? (가치 추산)
여기서 상태가치함수(V)를 추산하는 방법중 하나가 "몬데카를로 기법" 이다.
몬테카를로 기법 이론
몬테카를로 기법이란
=> 계산하기 어려운 값을 "수 많은 시행"을 거쳐 추산 하는 방법을 뜻한다.
몬테카를로 기법으로 상태가치 함수 추정하기
- V => 여러 시나리오의 가치 합산의 기대값
- 따라서 여러 시나리오에 대해 "수 많은 시행"을 거쳐 기대값을 구하면
- 상태가치 함수를 추산 할 수 있음

임의의 행동 정책 (π) 아래서
존재하는 여러 에피소드들을 수행해본다.
그리고 각 상태와 행동으로 부터의 보상을 평균낸다
=> Vπ(s, a)에 대한 값을 통해 => 가치 함수 역산
하지만 이렇게 계산을 하면, 모든 에피소드에서 모든 상태와 행동을 탐색해야하고
그말은 너무 많은 메모리와 연산을 사용한다는 것이다.
몬테카를로를 활용한 정책반복 알고리즘
반복:
에피소드 시작
반복:
현재 상태 <- 환경으로 부터 현재 상태 관측
현재 행동 <- 에이전트의 정책함수(현재 상태)
다음 상태, 보상 <- 환경에 '현재 행동'을 가함
if 다음 상태 == 종결상태:
반복문 탈출
에이전트의 가치함수 평가 및 정책함수 개선
env.reset()
step_counter = 0
while True:
print("At t = {}".format(step_counter))
env._render()
cur_state = env.observe()
action = mc_agent.get_action(cur_state)
next_state, reward, done, info = env.step(action)
print("state : {}".format(cur_state))
print("aciton : {}".format(action_mapper[action]))
print("reward : {}".format(reward))
print("next state : {} \n".format(next_state))
step_counter += 1
if done:
break
행동 선택 (e-greed 정책 사용)
def get_action(self, state):
prob = np.random.uniform(0.0, 1.0, 1)
# e-greedy policy over Q
if prob <= self.epsilon: # random
action = np.random.choice(range(self.num_actions))
else: # greedy
action = self._policy_q[state, :].argmax()
return action※ greedy정책 / e-greedy 정책
간단하게 e-greedy정책은,
'항상 하던행동이 아니라, 한번 쯤은 해보지 않은 행동을 해보자!"
를 구현하기 위한 정책임
왜 e-greedy가 필요한가?
=> 매번 하던 행동만 하면, 더 좋은 길이 있어도 알 수가 없음
=> 그래서 "때때로"는 가보지 않았던 길도 가봐야함
배운것 소화하기
강화학습은
- 환경에 대한 정보 (상태, 행동, 보상)가 있을 때는 => 최적의 행동 정책을 찾기 위해 동적계획법 사용
- 하지만 현실에서는 환경에 대한 정보가 없는 경우가 많기 때문에, 최적 행동을 찾는 다른 방법이 필요
몬테카를로 기법은
- 수많은 시도를 통해 => 어떤 값을 추정하는 방법
- 강화학습에서는 여러 행동을 통해 얻어지는 보상을 통해 => 가치함수를 추정할 때 사용
끝.
'IT > Machine learning' 카테고리의 다른 글
| [ML/python] python 코드 작성시 자잘한 내용들 (2023-01-23 updated) (0) | 2023.01.23 |
|---|---|
| [ML/강화학습] 강화학습 flow (0) | 2022.10.05 |
| [강화학습] 강화학습 이론_비동기적 동적계획법 (0) | 2022.10.03 |
| [강화학습] 최적의 행동은 어떻게 찾을까? _ 동적계획법 (feat 정책반복) (0) | 2022.10.03 |
| [강화학습] 강화학습관련 수학이론_마르코프 결정 과정(MDP) (0) | 2022.09.30 |
- Total
- Today
- Yesterday
- Unity
- requests
- 강화학습
- 터틀트레이딩
- C#
- PYTHON
- IT기초
- 기초
- 파이썬
- ET5X
- 주식
- 경영학
- 심리학
- 프로그래머스
- 유니티
- 비전공자
- It
- 머신러닝
- json
- Anet
- beautifulsoup
- 알고리즘
- 마케팅
- 시스템투자
- 스타트업
- 일자별
- 크롤링
- 가격데이터
- 주식투자
- 랜덤맵
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |