
티스토리 뷰
이전에는 마르코프 결정 과정 (MDF : Markov Decision Process)을 통해
강화학습의 문제가 결국 "행동을 선택하는 최적의 정책" π*을 찾는 것이라고
어렴풋이 알게 되었다.
하지만, π*는 정해진 해가 없기 때문에 특정 알고리즘을 통해 최적해를 찾아가야하는 문제가 남아있다.
동적계획법(DP : Dynamic Programming)은 마르코프 결정 과정에서 최적의 정책을 찾기 위한
문제풀이방법 중 하나이다,
동적계획법(DP : Dynamic Programming)
=> 복잡한문제를 작은문제로 쪼개서 답을 구하는 방법을 뜻한다
큼 음식을 한번에 먹는 것이 아니라, 그것을 1000조각을 내서
작은 음식을 1000번 먹으면 되는 것처럼
복잡한 문제를 한번에 해결하는 것이아닌, 작고 쉬운 문제로 쪼개어 그것을
여러번 해결하는 방법이다.


동적계획법이 해결할 수 있는 문제의 특징
- 최적하위구조 (Optimal substructure) : 분할한 작은 문제의 최적값이 큰 문제에서의 최적값 => 음식을 아무리 쪼개도 맛있는 부위는 같다
- 중복하위문제 (Overlapping problems) : 따라서, 큰 문제의 해를 구하기 위해서 작은 문제의 최적 해를 재사용
※ MDP에서 π*를 찾는 것은 이 특성을 만족한다
동적계획법으로 π* 찾기 = 정책반복 = 정책평가 + 정책개선
1. 정책평가(PE : Policy Evaluation)
의미 : 현재의 행동정책π 에서 얻을 수 있는 최대의 가치 max(Vπ(s, a)) 계산
가치의 계산은 Bellman expectation backup operator 를 사용하여 계산

위의 식을 분석해 보면
다음가치 = (1) + γ*(2)*이전가치

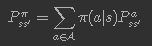
따라서 Bellman expectation backup operator 가 말하는 "가치" 란
"주어진 행동 정책에 따랐을 때, 현재와 미래의 모든 상태에서 얻어지는 보상의 현재가치의 합"
알고리즘 Part

2. 정책개선(PI : Policy Improvement)
의미: 지금보다 더 높은 가치Vπ(s, a) 를 창출 할 수 있는 새로운 정책 π'를 계산

3. 정책 반복
=> 정책평가와 정책개선을 반복 => 수렴값 π*
=> 정책평가 : 임의의 π에 대해 최대 상태 가치 계산
=> 정책개선 : 더 높은 상태 가치를 가지는 새로운 π'을 계산
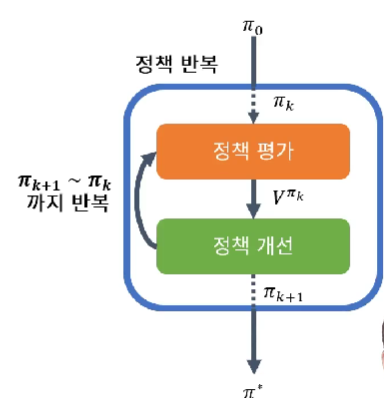
언제까지?
이전의 행동정책으로 부터의 가치와
새로운 행동정책으로 부터의 가치 차이가 거의 같아질때 까지
"결국 최대 상태가치를 가지는 π*에 수렴"
배운것 소화하기
결국 찾고자 하는 것은 주어진 환경에서 최적의 행동 정책(π*)을 찾는 것이다.
행동 정책이란, 어떻게 행동 해야하는지를 표현한 것인데
수학적으로는 특정 행동이 일어날 가능성들의 집합을 뜻한다.
주어진 환경이란
- 상태들 S
- 각 상태에서 취할 수 있는 행동들 A
- 각각의 상태s 에서 어떤 행동a 을 취했을 때 얻을 수 있는 보상 R
동적계획법이란, 최적의 행동을 찾을 때 사용하는 하나의 방법론 이다.
동적계획법은
- 큰 문제를 작고 쉬운 문제들로 쪼개어 최적해를 구하는 방법이다
- 풀이 과정이 반복적인 경우 효과적이다
동적계획법을 이용하여 최적의 행동을 찾기 위해 다음과 같은 방법(정책 반복)을 쓴다
- 정책평가 : 주어진 π에 대해 최대 상태 가치 계산
- 정책개선 : 더 높은 상태 가치를 가지는 새로운 정책 π'를 계산
- 1)번과 2)번을 반복한다
끝.
'IT > Machine learning' 카테고리의 다른 글
| [ML/강화학습] 강화학습의 기본 이론_ 몬테카를로를 활용한 정책반복 (0) | 2022.10.03 |
|---|---|
| [강화학습] 강화학습 이론_비동기적 동적계획법 (0) | 2022.10.03 |
| [강화학습] 강화학습관련 수학이론_마르코프 결정 과정(MDP) (0) | 2022.09.30 |
| [ML] 머신러닝(Machine learning) 학습 방법_지도학습, 비지도학습, 강화 학습 (2) | 2022.09.30 |
| 머신러닝 vs 딥러닝 (0) | 2020.05.18 |
- Total
- Today
- Yesterday
- 기초
- 강화학습
- C#
- 프로그래머스
- 파이썬
- 스타트업
- 주식
- 가격데이터
- 일자별
- PYTHON
- 시스템투자
- 터틀트레이딩
- 랜덤맵
- IT기초
- 크롤링
- 머신러닝
- 마케팅
- beautifulsoup
- 비전공자
- 유니티
- json
- Anet
- 경영학
- 알고리즘
- Unity
- 주식투자
- It
- requests
- 심리학
- ET5X
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |