
티스토리 뷰
오늘 배울내용 이전에 알아야할 내용은 다음과 같다.
동적계획법으로 최적의 행동 정책π을 구하는 과정에서 While문을 두번 사용해야 한다
- 정책평가 할 때
- 정책반복 할 때
이것을 하나로 줄일 수 있는 방법이 있는데,
가치 반복 (VI : Value Iteration)이다.
가치반복 (VI : Value Iteration)

개념은 간단하다.
이전에는 정책평가(PE)에서 평균값에 수렴시켰다면,
가치반복에서는 가치값을 최대값으로 수렴시켰다는 점이다.
근데 여기서 한가지 문제점이 발생하게 되는데
최적값을 찾는 과정에서 원래 정책개선에 포함되어 있던 "불필요한 행동 제거"가 없어지게 되기 때문에
계속 전체 경우의 수를 모두 고려해야 된다 => 계산량이 많다!
이때 등판하는 것이
비동기적 알고리즘 필요!!
비동기적 알고리즘?
왜 비동기적 동적계획법이라는 말을 쓰는지는 모르겠지만,
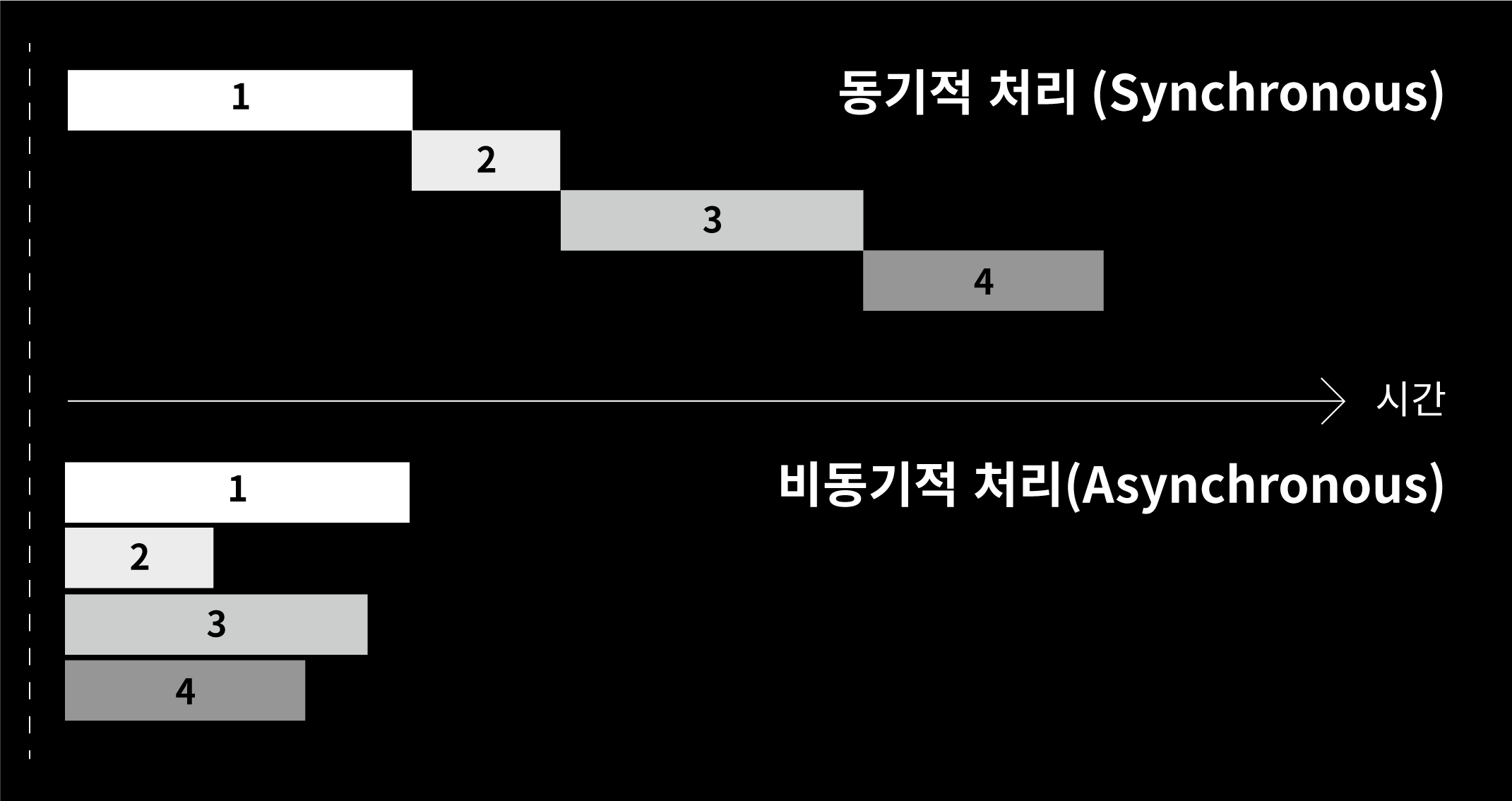
동기적 = 이전 일이 끝나야, 그다음일을 수행
비동기적 = 다른일을 하고 있다가, 이전일이 끝나면 그에 대한 추가 작업만 시행


비동기적 동적 계획법의 종류
- In-place DP => 있는 자료로 없는 자료 계산
- Prioritized sweeping => 벨만 에러(bellman error)가 큰 상태부터 계산 => 우선순위 부여
- Real-time DP => 현재 상태가 과거의 모든 상태에 대한 정보를 가지고 있다는 마르코프 특성 활용
중요한 것은 동기적 보다는 비동기적으로 하는 것이 더 효율적이다!
끝.
728x90
'IT > Machine learning' 카테고리의 다른 글
| [ML/강화학습] 강화학습 flow (0) | 2022.10.05 |
|---|---|
| [ML/강화학습] 강화학습의 기본 이론_ 몬테카를로를 활용한 정책반복 (0) | 2022.10.03 |
| [강화학습] 최적의 행동은 어떻게 찾을까? _ 동적계획법 (feat 정책반복) (0) | 2022.10.03 |
| [강화학습] 강화학습관련 수학이론_마르코프 결정 과정(MDP) (0) | 2022.09.30 |
| [ML] 머신러닝(Machine learning) 학습 방법_지도학습, 비지도학습, 강화 학습 (2) | 2022.09.30 |
공지사항
최근에 올라온 글
최근에 달린 댓글
- Total
- Today
- Yesterday
링크
TAG
- 유니티
- C#
- IT기초
- 비전공자
- beautifulsoup
- 랜덤맵
- 알고리즘
- PYTHON
- 주식투자
- json
- 강화학습
- 터틀트레이딩
- requests
- Anet
- 크롤링
- 머신러닝
- 주식
- 프로그래머스
- 심리학
- 일자별
- 시스템투자
- ET5X
- 스타트업
- 가격데이터
- 파이썬
- Unity
- 마케팅
- 경영학
- It
- 기초
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
글 보관함
250x250