
티스토리 뷰
다양하게 크롤링 하는 방법은 아래 링크를 통해 알 수 있다.
requests, get방식>
<request, post방식>
셀레니움 selenium으로 다나와 사이트 크롤링 하기 ☜
이글을 이해하기 위해서는
- 서버와 클라이언트의 개념을 알면 좋다.
- 서버와 클라이언트의 통신 방법 (get, post등)의 개념을 알면 좋다
- HTML이 무엇인지, 그리고 HTML의 구조에 대해 알면 좋다.
크롤링 대략적인 순서도

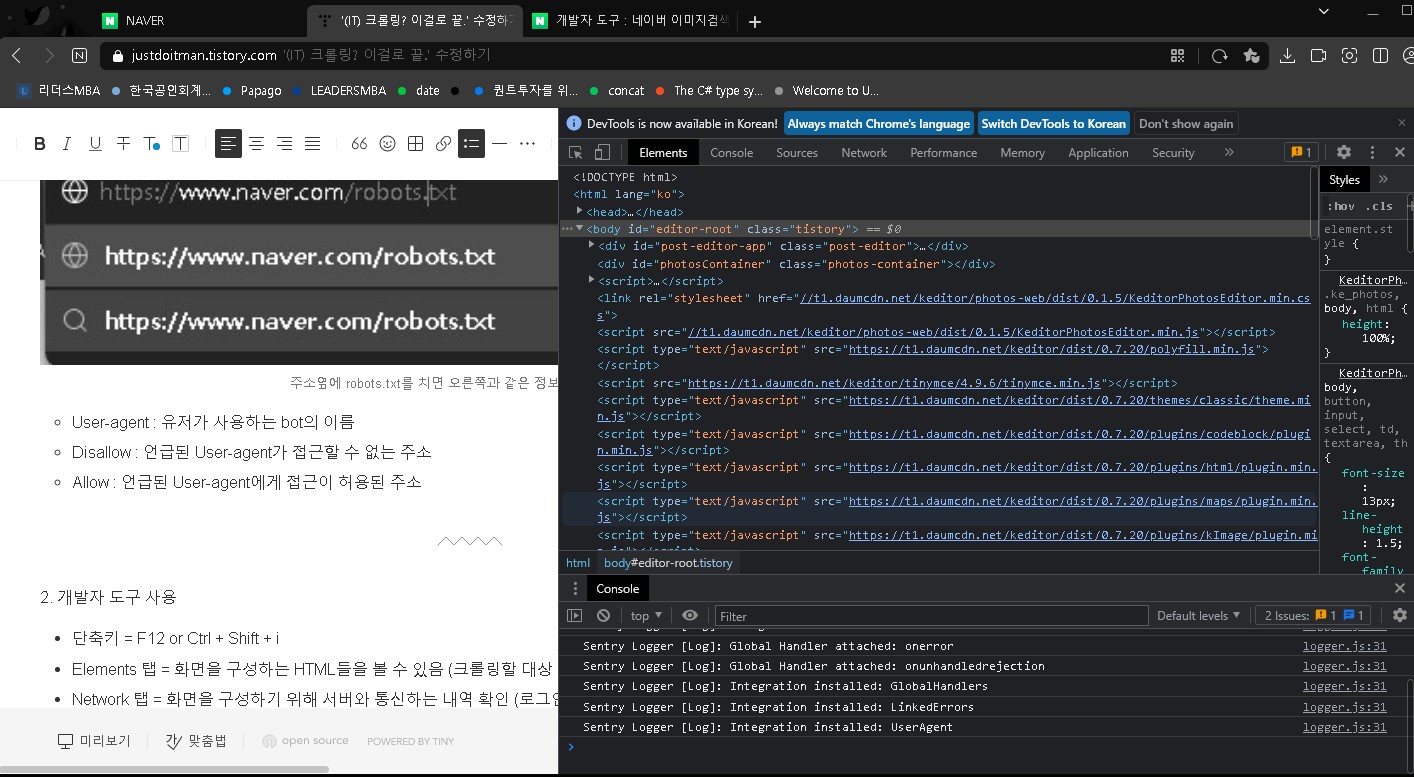
1.사전준비 (robots.txt)
- 주소/robots.txt
- 웹페이지에 접근이 허용된 User-agent 확인
- 웹페이지에 접근 가능한지 여부 확인


- User-agent : 유저가 사용하는 bot의 이름
- Disallow : 언급된 User-agent가 접근할 수 없는 주소
- Allow : 언급된 User-agent에게 접근이 허용된 주소
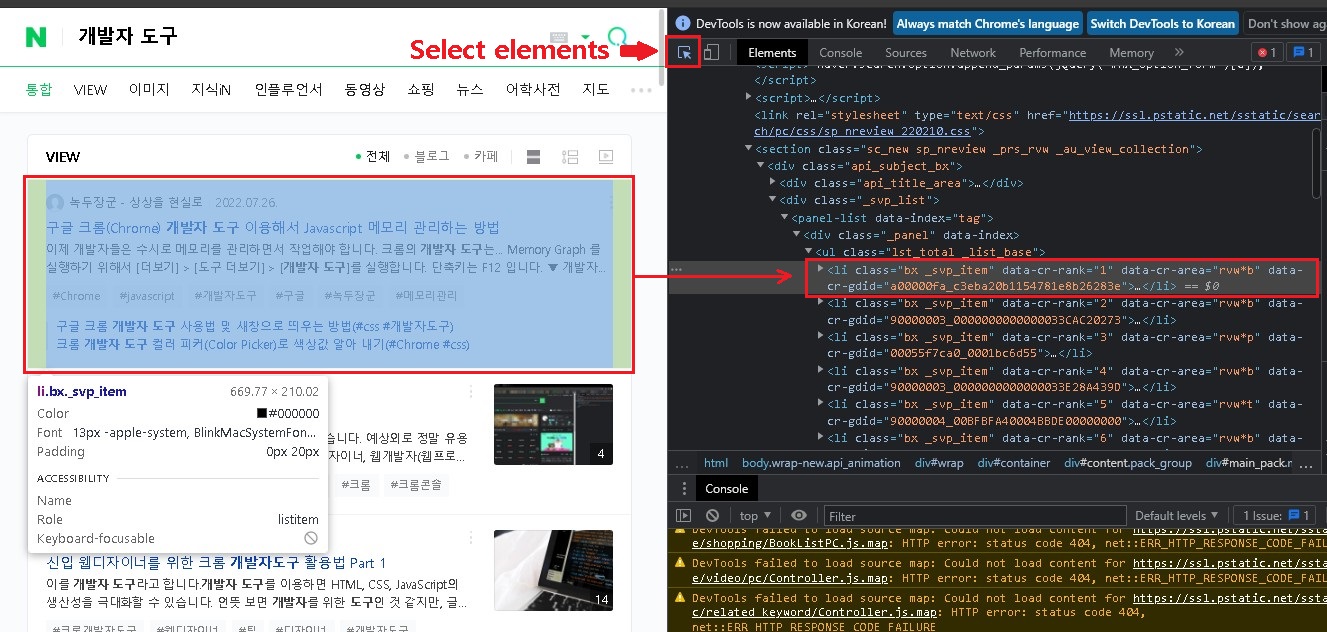
2. 크롤링 필수 정보 확인 (개발자 도구)
- 단축키 = F12 or Ctrl + Shift + i
- Elements 탭 = 화면을 구성하는 HTML들을 볼 수 있음 (크롤링할 대상 확인)
- Network 탭 = 화면을 구성하기 위해 서버와 통신하는 내역 확인 (로그인, Javascript 내용 확인)
<Element 탭>
- 크롤링할 대상의 위치 확인= Select Element (Ctrl + Shift + C)
- 대상의 주소 확인하기
크롤링할 대상을 찾았다면,
이제 그대상의 '위치'정보 즉, 주소를 알아야 한다.
그래야 나중에 해당 정보를 찾아 갈 수 있다.
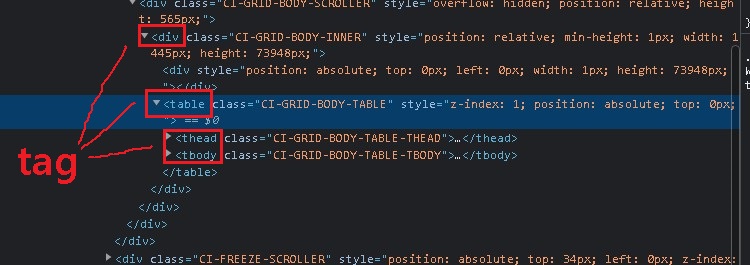
주소의 종류에는 3가지가 있다.
- HTML Tag
- CSS selector
- XPath


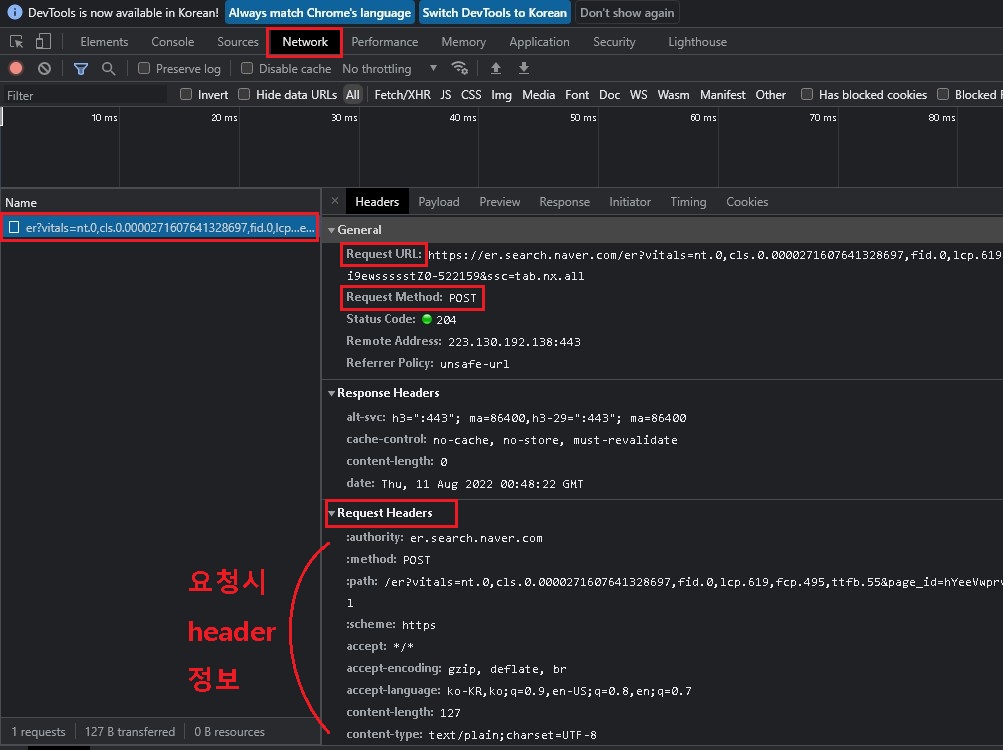
<Network 탭>
- 데이터 요청방식 확인 (get방식, post 방식)
- request header 정보 확인
- Payload에서 요청시 필요한 parameter 정보 확인
※ get방식 post방식???
get방식과 , post방식이란 인터넷에서 서버와 클라이언트가 정보를 주고 받는 방식이다.
대충 쉽게 말하자면
A라는 사람이 B라는 사람에게 편지를 줄때
get방식은 편지봉투에 요청내용을 적어서 보내주는 방식이고
post방식은 요청내용을 봉투 안에 넣어서 보내주는 방식이다.
get방식은 간편하지만, 보안에 취약하고, 요청내용에 제한이 있다
post방식은 상대적으로 안전하다. 또한 많은 내용을 요청 할 수 있다.



핵심은 데이터를 서버에 요청해서 받아오기 위해 알아야할 모든 정보는
개발자 도구에서 확인 할 수 있다는 것!!
3. 웹에서 데이터 가져오기 + 4. 가져온 데이터 가공하기(추출)
- 그냥 크롤링 하기= requests, get방식
- 로그인이 필요할 때 = requests, post방식
- Javascript(ajax) 방식으로 화면이 그려질때 = request, post방식
- 사람 처럼 크롤링 하기 = 브라우저를 통해 (selenium)
- 원하는 데이터만 추려내기 (BeautifulSoup)
데이터를 가져오기 위해서는 서버에 데이터를 요청해야 한다.
다양하게 크롤링 하는 방법은 아래 링크를 통해 알 수 있다.
requests, get방식>
<request, post방식>
셀레니움 selenium으로 다나와 사이트 크롤링 하기 ☜
5. 데이터 활용 및 저장하기
- datafame
- DataBase (sql)
끝.
'IT > IT 이것 저것' 카테고리의 다른 글
| [논문해석] Semi supervised(준지도 학습)을 활용한 모바일 제품명 추출하기 (0) | 2022.09.08 |
|---|---|
| [IT, 통계]문자열 전처리 내용 정리 (0) | 2022.09.03 |
| (주식 자동 매매) Naver에서 가격 정보 업데이트 자동화_윈도우, anaconda환경(feat, 작업스케쥴러) (0) | 2022.07.27 |
| 비전공자를 위한 IT지식_Json 자료형식이란 (0) | 2022.07.25 |
| (주식 자동 매매) 네이버에서 KOSPI 종목 일자별 가격 정보 크롤링 하기 (feat. beautifulsoup, dataframe) (0) | 2022.07.21 |
- Total
- Today
- Yesterday
- C#
- 알고리즘
- IT기초
- 터틀트레이딩
- requests
- Anet
- It
- 기초
- 심리학
- 프로그래머스
- 가격데이터
- 크롤링
- 파이썬
- 일자별
- 강화학습
- 스타트업
- 비전공자
- Unity
- ET5X
- PYTHON
- json
- 주식투자
- beautifulsoup
- 경영학
- 시스템투자
- 마케팅
- 랜덤맵
- 유니티
- 주식
- 머신러닝
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |