
티스토리 뷰
※ 본문의 내용은 Mobile Phone Name Extraction from Internet Fprums: A Semi-supervised Approach, Yangjie Yan, Aixin Sun의 내용을 요약 정리한 내용이며, 모든 장표와 이미지의 출처는 해당 논문에서 발췌한 것입니다.
자신의 제품이 시장에서 어떤 반응을 보이고 있는지 알고 싶은 마케터라면
혹은, 경쟁사 제품에 대한 시장현황을 분석하고 싶은 기업 대표라면
한번 쯤 생각해 보았을 것이다.
"어떤 글에서 특정 제품이 언급되어있는지 여부를 알 수 있다면, 해당 제품에 대한 시장 data를 얻을 수 있을텐데... "
하지만, 어떤 제품이 언급이 되었는지를 확인하는 것은 굉장히 어렵다.
왜냐하면 오타, 별명, 줄임말 등을 사용하기 때문이다.

본 논문은 특정 제품이 문장속에서 언급이 되었는지, 어떤 제품이 언급이 되었는지 확인 하는 방법을 제시하고자 한다.
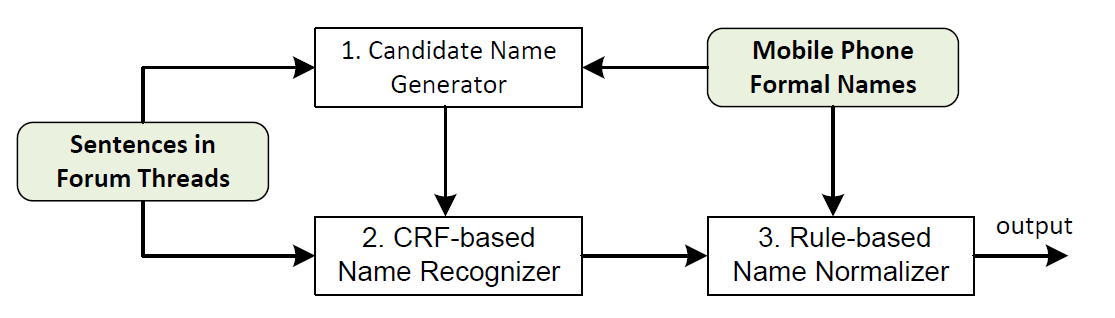
OverView
구현할 내용
- 제품명을 언급한 것인지 인식 : NER (Named Entity Recognition)
- 언급된 제품명을 하나의 통일된 제품명으로 전환 : NEN (Named Entity Nomalization)

input data
- 제품의 공식명칭 데이터 (Mobile phone formal names)
- 분석하고자하는 글 데이터 (Sentence in forum threads : ex, 댓글, 기사, SNS후기 등)
사용하는 모델의 3단계 (GREN)
- 1단계 : 후보군 생성 (candidate name Generator)
- 입력값 = 분석하고자 하는 글 데이터 (Sentence in forum threads : ex, 댓글, 기사, SNS후기 등)
- 결과값 = 상품명 후보리스트 C
- 활용한 알고리즘 = 클러스터링 알고리즘
- 후보군 생성 = 제품명이 될 수 있는 잠재적 후보군
- 모델명만 있는 경우 ex) 겔럭시 s10
- 모델명 + 브랜드명(회사명)이 언급된 이후의 제품명 ex) '겔럭시 s10' 언급 이후, 다시 언급된 's10'
- 2단계 : CRF기반의 이름 인식 (CRF-based name REcognizer)
- 입력값
- 제품의 공식명칭 데이터 f (Mobile phone formal names)
- 숫자는 아라비아 숫자와 로마숫자 모두 포함
- 제품명이 브랜드명 + 모델명으로 이루어진 경우 => 모델명도 모두 포함
- 분석하고자 하는 글 데이터 (Sentence in forum threads)
- 제품의 공식명칭 데이터 f (Mobile phone formal names)
- 결과값 = '상품명' 후보 리스트 C
- 상품명인지 아닌지 확인하기 위해 활용하는 특징
- 단어의 어휘적 특성, 스펠링 (lexical feature) = L
- 단어의 문법적 특성 (grammatical feature) = G
- 제품명의 특성 (feature from candidate name) = N
- 입력값
- 3단계 : 단어의 활용을 통한 이름 표준화 (lexcial rule-based name Normalizer)
- 입력값 = 상품명 후보리스트 C
- 결과값 = 상품명으로 분류된 단어들 Lf
- 알고리즘 L
- C안에서 공식명칭과 같은 알파벳을 가지고 있으면서, 동일한 순서를 포함하고 있는 경우 Lf에 포함
- case1에서 Lf에 포함된 내용들을 => tokenize(띄어 쓰기 단위로 분류) => 그리고 C에서 tokenize된 단어를 포함하고 있는 단어들을 Lf에 포함
- 신뢰도 점수 활용하여 최종 분류 => 제목이나과 설명란에 제품명이 있는 글이 있는 경우 => 해당글에 한번도 나타나지 않은 단어는 신뢰도를 0으로 판단하여 제외 (즉, 이건 별도의 계산이 필요)

1단계 : 후보군 생성 (candidate name Generator)
논문에서는 핸드폰 이름의 구성을 3가지로 분류 하였다
| Brand | Model name | Model Number |
| samsung | Galaxy s10 | I9300, I9305 |
| apple | iPhone 11 | - |
| Sony | Xperia S | LT26 |
나는 이렇게 분류해보고 싶다 [추가]
| Company name (Milestone) | Product name | Serise name | Variation name |
| samsung | Galaxy | s6, s7, s10, ... | +, plus, 5G, LTE |
| samsung | Note | 10, 11 ... | +, plus, 5G, LTE |
| apple | iPhone | 6, 7 ,8 ,X ... | +, plus, mini, pro, pro max |

1. 단어 분류 (clustering)
단어 중에서 "브랜드명", "모델명"에 해당하는 단어 추출 = clustering
클러스터링 알고리즘 (단어 생김새의 유사성)
- Brown clustering http://www.derczynski.com/sheffield/brown-tuning/
- k-mean : https://blog.naver.com/hjy5405/222593465007
from brown_clustering_yangyuan import *
import pandas as pd
from nltk.tokenize import RegexpTokenizer
forum_posts = pd.read_csv("../input/meta-kaggle/ForumMessages.csv")
# take first 100 forum posts
sample_data = forum_posts.Message[:100].astype('str').tolist()
# toeknize
tokenizer = RegexpTokenizer(r'\w+')
sample_data_tokenized = [w.lower() for w in sample_data]
sample_data_tokenized = [tokenizer.tokenize(i) for i in sample_data_tokenized
corpus = Corpus(sample_data_tokenized, 0.001)
clustering = BrownClustering(corpus, 6)
clustering.train()
clustering.get_similar('kaggle')from brown_clustering import BigramCorpus, BrownClustering
# use some tokenized and preprocessed data
sentences = [
["This", "is", "an", "example"],
["This", "is", "another", "example"] ]
# create a corpus
corpus = BigramCorpus(sentences, alpha=0.5, min_count=0)
# (optional) print corpus statistics:
corpus.print_stats()
# create a clustering
clustering = BrownClustering(corpus, m=4)
# train the clustering
clusters = clustering.train()
# use the clustered words
print(clusters)
# [['This'], ['example'], ['is'], ['an', 'another']]
# get codes for the words
print(clustering.codes())
# {'an': '110', 'another': '111', 'This': '00', 'example': '01', 'is': '10'}
2.예상되는 여러 표현방법(Variation) 후보군 생성
- Soundex, Metaphone 알고리즘 (발음의 유사성)
- 두 단어의 첫머리 단어 끝단어가 같은 경우 ex) samsung , semsedg
- 첫 3개의 단어가 같은 경우 ex) samsung, samsen
- 브랜드 이름에 1개 이상의 대문자가 있는경우 => 그것을 소문자로 표현한 경우 ex) BlackPink => bpink, bpk, bp...
- 단어가 6개 글자 이상인 경우 (단어가 5개 이하인 경우에는 variation이 거의 발생하지 않음)
>>> import jellyfish
>>> jellyfish.levenshtein_distance(u'jellyfish', u'smellyfish')
2
>>> jellyfish.jaro_distance(u'jellyfish', u'smellyfish')
0.89629629629629637
>>> jellyfish.damerau_levenshtein_distance(u'jellyfish', u'jellyfihs')
1
>>> jellyfish.metaphone(u'Jellyfish')
'JLFX'
>>> jellyfish.soundex(u'Jellyfish')
'J412'
>>> jellyfish.nysiis(u'Jellyfish')
'JALYF'
>>> jellyfish.match_rating_codex(u'Jellyfish')
'JLLFSH'
3. 최종 제품명 후보군(C) 추출
- 문자열에서 브랜드명이 언급된 경우
- 앞에서 브랜드명이 언급된 이후에, 모델명이나 브랜드명이 언급된 경우 해당 문자열
- 문장에서 모델명이 언급된 경우 [추가]
2단계 CRF모델을 통한 제품명 인식 (CRF-based name REcognition)
1. 훈련 data선별을 위한 기준
- P = 정규 명칭 그룹 by rules bleow
- 로마숫자와 아라이바숫자 모두 포함 ex) s3, sⅢ
- 브랜드명(회사)과 모델명이 같이 있는 경우 only모델명도 포함 ex) Samsung Galaxy s3, Galaxy s3
- 시리즈명도 포함 [추가]
- 만약 Samsung Galaxy S3 => P = [Samsung Galaxy S3, Samsung Galaxy SⅢ, Galaxy S3, Galaxy SⅢ, S3, SⅢ]
- N = 정규 명칭 제외 그룹 <= 직접 선출 from 최종 제품명 후보군(C)
- C = 1단계에서 생성된 최종 제품명 후보군
2. 훈련 data 선별
- 정규 명칭 그룹(P or N)에 속해있는 단어가 포함된 경우
- 최종 제품명 후보군(C)에는 있지만 정규명칭 그룹(P or N)에는 없는 단어가 포함된 경우
3. 문장의 성격 분류 (features)
- 문장에서 제품명을 이루문장들은 띄어쓰기가 아닌 '_(under bar)'로 구분 => clustering의 효과를 올리기 위해


- N1 : 현재의 단어와 양옆으로 둘러싼 단어들에
- N2 : Brand entropy를 계산
- 문장에 제품 후보군(C)이 없는 경우 N2 = 0
- 문장에 제품 후보군(C)이 있는 경우 N2 = 1
- 브랜드명을 포함하지 않은 제품후보군(C)이 있는 경우,
- m = 임의의 브랜드가 언급된 이후에 후보군 c가 언급된 횟수
- mb = 특정 브랜드b가 언급된 이루에 후보군 c가 언급된 횟수
- 후보군c가 특정 브랜드b의 모델일 확률 P(c, b) = mb/m
- 후보군c에 대한 브랜드 엔트로피 모든 b에 대해 - ∑ P(c,b)*logP(c,b)
4. 라벨링 with CRF
- CRF model에서 사용한 규칙(scheme) = YNO (Yes-No-Out) scheme
- YNO scheme = 만약 어떤 단어가 P에 속한다면 'Y', N에 속한다면 'N', 둘 모두에 속하지 않는 것은 'O'로 분류
- 즉, 이게 상품명인지 아닌지에 대한 라벨링
3단계 : 단어의 활용을 통한 이름 표준화 (lexcial rule-based name Normalizer)
지금까지 문장속에서 어떤 단어가 '상품명'으로 분류 되는지 여부를 판단했다.
3단계는 이렇게 '상품명'으로 분류된, 단어를 다시 => 동일한 실제 상품명에 맵핑하는 과정이다.
ex) [s3, sam s3, galaxy s3, gal s3 ... ] => Samsung Galaxy S3
이미 상품명인지 아닌지를 식별하기 위해서 우리는 사전적으로 표준화를 했지만
후보군 C에는 아직도 여러 noise data들이 들어 있다.
그래서 상품명으로 분류된 단어들에 대해 각각의 신뢰성을 측정하여하는 알고리즘(Lf)를 만들어 표준화 한다

1. 후보군C에 포함된 단어들의 알파벳이, 공식이름 f에 포함된 단어에도 들어있고 순서도 같은 경우에 Lf에 포함시킨다.
ex) sgs3, samsung s3, gal s3, galaxy 3 <= Samsung Galaxy s3
2. 위의 단계를 거쳐서 Lf로 분류된 문자열들을 tokenize => 각각의 token들이 포함되어 있는지 여부를 한번더 확인
ex) sgs 3, samsung s3, gal s3, galaxy 3... => sgs, 3, samsung, s3, gal, galaxy ..
3. 마지막으로, Lf에 포함된 단어들의 신뢰도를 평가
- 제목등에 제품명이 포함된 글의 경우 => 해당 글에서 한번도 언급이 안된 단어들이 있다면 => 신뢰도가 낮은 단어임
- 신뢰도가 낮은 단어들은 Lf에서 제거
- 예를들어 SII ∈ SIII 인 경우가 발생 할 수 있기 때문에
[참고]관련한 다른 실험
- NER (Named Entity Recognition) = 단어 인식 및 분류 => 해당 단어가 어떤 의미인지 구분하는 것
- FS-NER system : CRF보다 3%정도 정확성이 높음
- KNN(K-Nearest Neigbors) + CRF
- NEN (Named Entity Nomalization) = 인식된 단어들을 같은의미의 그룹으로 묶는 과정
- 기존의 NEN은 많은 dataset을 통한 학습이 필요
- 하지만 이 논문에서 소개하는 GREN process는 training examples가 필요 없음
참고 자료
준학습 (Semi supervised model) https://blog.naver.com/estpublic/222140321884
CRF 모델
자연어 처리 NER : Named Entity Recognition https://stellarway.tistory.com/29
자연어 처리 NEN (Named Entity Nomalization)
- N-Gram https://wikidocs.net/21692
'IT > IT 이것 저것' 카테고리의 다른 글
| [자연어 처리] CRF in python (0) | 2022.09.12 |
|---|---|
| [자연어 처리]Jellyfish_문장,단어의 유사도 파악하기 (0) | 2022.09.12 |
| [IT, 통계]문자열 전처리 내용 정리 (0) | 2022.09.03 |
| (IT) 크롤링 기본? 이걸로 끝. (0) | 2022.08.10 |
| (주식 자동 매매) Naver에서 가격 정보 업데이트 자동화_윈도우, anaconda환경(feat, 작업스케쥴러) (0) | 2022.07.27 |
- Total
- Today
- Yesterday
- C#
- requests
- 스타트업
- 경영학
- 알고리즘
- 기초
- 터틀트레이딩
- 크롤링
- 가격데이터
- Anet
- 강화학습
- json
- 마케팅
- It
- 주식
- ET5X
- 심리학
- 비전공자
- 주식투자
- 랜덤맵
- 유니티
- 일자별
- Unity
- 프로그래머스
- 시스템투자
- PYTHON
- 머신러닝
- IT기초
- 파이썬
- beautifulsoup
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |