
티스토리 뷰
(주식 자동 매매) 네이버에서 KOSPI 종목 일자별 가격 정보 크롤링 하기 (feat. beautifulsoup, dataframe)
KS짱짱맨 2022. 7. 21. 16:14naver에서 종목별, 일자별 가격 data를 받아오는 코드를 작성해 보겠다
사실 키움증권API나 ystockquote등을 사용해서 주식시세 데이터를 불러오는 방법도 시도했었으나,
- 키움증권API는 데이터 제한이 있어서 활용이 너무 어려웠고 + 시간이 오래걸리는 문제가 있엇고
- ystockquote 같은 경우에는 실제 시세 데이터와의 차이가 있어서
naver주식 탭에서 시세데이터를 그냥 긁어와보기로 했다.
이 포스트를 통해 배울 수 있는 것들
- header을 통해 "사람이 인터넷을 통해 접근하는 것처럼 접속"해서 crawling 하는 방법
- Dataframe에서 행병합, 열병합 하는 방법
- Dataframe으로 파일 불러오고 저장하는 방법
만약, 크롤링이 처음이라면
이 포스터를 읽기 전에 기본적인 크롤링 방법에 대해 숙지하면 더욱 좋을 것 같다 :)
30초만에 크롤링!! 크롤링 기초 배우러가기 ☜
네이버에 시세를 확인 할 수 있는 페이지가 있고
https://finance.naver.com/item/sise.naver?code=035720
이 url은 두가지로 구분되어 있다.
- 본주소 부분 : https://finance.naver.com/item/sise.naver?code=
- 종목코드 부분 : 035720
따라서 KOSPI종목별 코드 리스트가 필요할 것 같다.
import requests
from datetime import datetime
import pandas as pd
from bs4 import BeautifulSoup as bs
def getCodeList():
df = pd.read_csv('kospi_list') #코스피 목록 불러오기
lists = df['종목코드'].values.tolist() #코스피 종목코드 리스트
return lists그래서 kospi_list라는 파일에서 종목코드를 '리스트' 변수로 반환해주는 함수를 만들었다.
--> 이 함수는 같은 폴더에 "kospi_list"라는 파일이 있어야 정상 작동 한다.
오늘의 목표인 일별시세 데이터는 위의 웹페이지 아래쪽에서 확인 할 수 있었다.
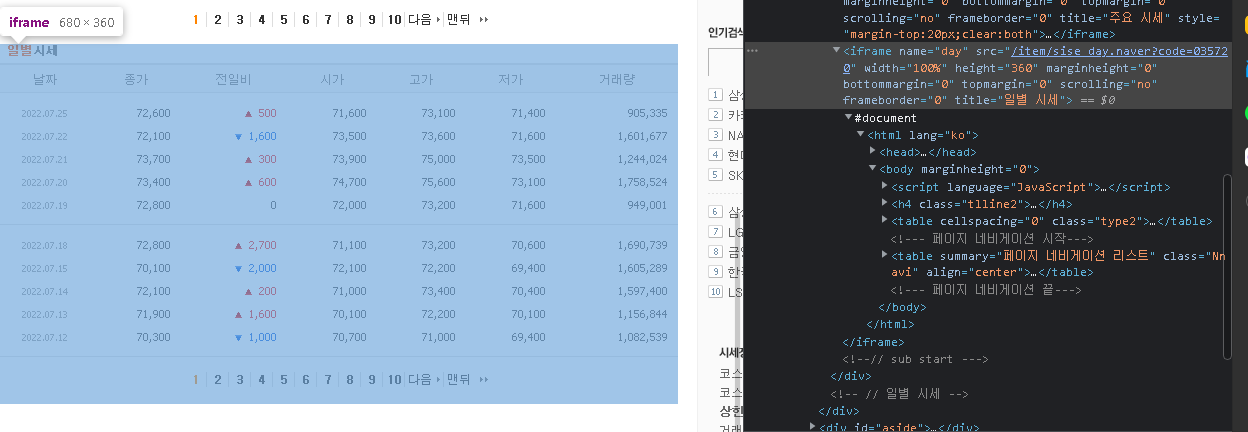
우선 iframe을 통해 크롤링을 시도해 보았으나... 내가 원하는 자료가 나오지 않았다.
F12를 눌러서 해당 화면을 확인해보니 아래와 같은 링크에서 자료를 받아오는 것을 확인 할 수 있었다.
https://finance.naver.com/item/sise_day.naver?code=035720
이 웹페이지 이름을 편의상 "일시세페이지" 라고 하겠다
하지만 여기서 무작정 크롤링을 시도하면 아무런 자료도 얻지 못하는데,
그 이유는 파이썬을 통해 "일시세페이지"에 접근하게 되면 존재하지 않는 주소라면서 접근이 안되기 때문이다 ㅠㅠ
url = 'https://finance.naver.com/item/sise_day.naver?code=' + code #data불러올 웹주소
req = requests.get(url=url) #get방식을 통해 url에 있는 데이터에 접근
rawData = bs(req.text, 'html.parser')위와 같이 코드를 짜게 되면 "rawData"에 아무것도 들어가지 않게된다!!!
그래서 알게 된 것이 바로 header를 이용한 방법이다.
위에 있는 코드가 아래처럼 바뀌게 된다.
url = 'https://finance.naver.com/item/sise_day.naver?code=' + code #data불러올 웹주소
headers = {'User-agent': 'Mozilla/5.0'} #★★크롤러가 아닌 웹브라우저에서 접속하는 것처럼 보이기 위한정보
req = requests.get(url=url, headers=headers) #get방식을 통해 url에 있는 데이터에 접근
rawData = bs(req.text, 'html.parser')자세히 보면
- header라는 딕셔너리 변수가 추가 되었고
- url에 접속 요청을 할때, 넘겨주는 인자에 url뿐 아니라 header가 추가되었다.
이렇게 하면 성공적으로 "일시세페이지"화면에 접근하여 정보를 얻어 올 수 있게 된다!!! (Yeah!!)
다시화면을 보면 아래와 같이 페이지별로 가격정보가 흩어져 있는 것을 볼 수 있다.
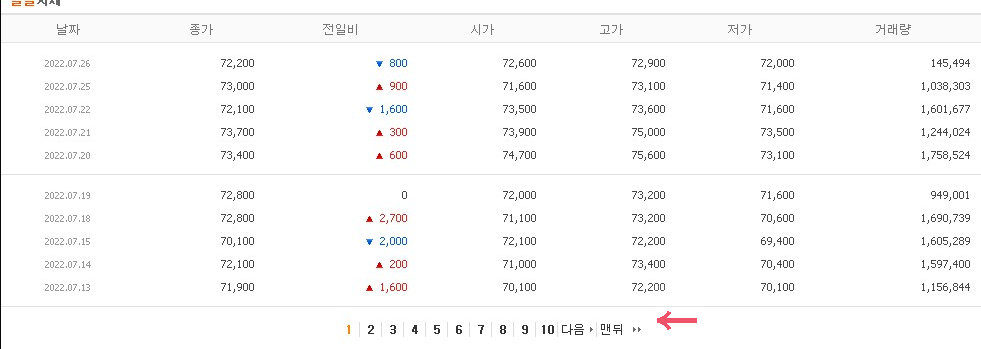
이제 종목별로 각각의 일시세페이지에서 정보를 가져와보자
URL = https://finance.naver.com/item/sise_day.naver?code=035720&page=1
인터넷 주소는 3부분으로 나뉜다
- 본주소 : https://finance.naver.com/item/sise_day.naver
- 종목정보 : ?code=035720
- 페이지정보 : &page=1
그러면 이제 Codelist에 있는 종목데이터를 주소의 종목정보에 넣고, 페이지 정보를 넣으면
각 종목별로 모든 페이지에 있는 테이터를 크롤링 할 수 있을 것이다.
그러기 위해서는 먼저 "가장 마지막 페이지"의 숫자를 알아야 했다.
모든 회사의 상장일은 다를 것이고 따라서 페이지 숫자도 각각 다를것이기 때문
일단 마지막 페이지 숫자에 대한 정보를 파악해본다
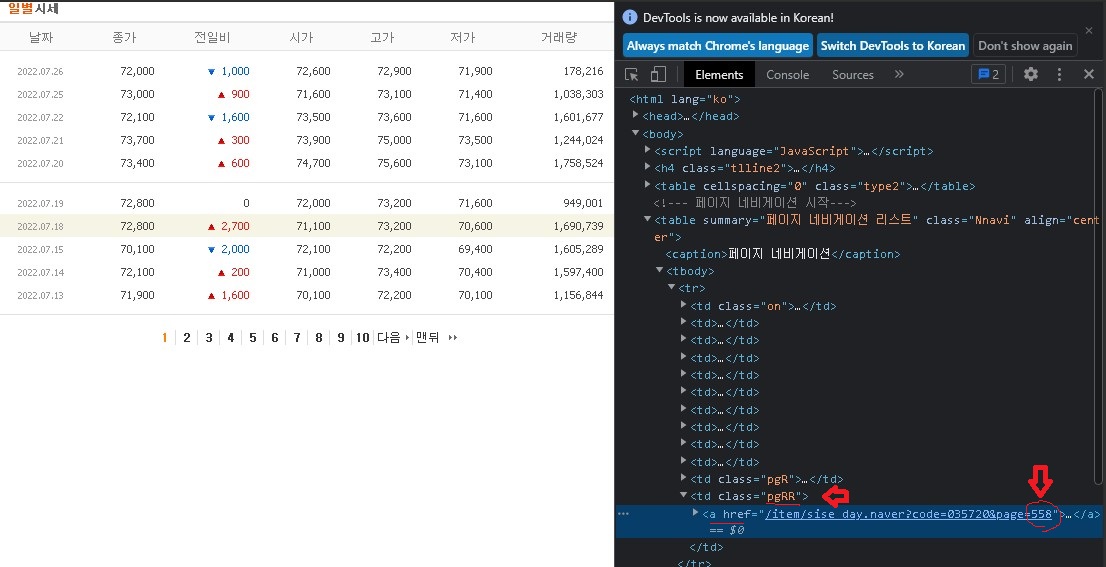
- 마지막페이지 정보가 들어있는 class 는 "pgRR"이다
- 링크주소 끝에 588이라는 숫자가 보인다
가장 마지막 페이지의 숫자를 가져오는 코드
pgRR = rawData.find('td', class_='pgRR') #마지막 페이지 정보가 있는 항목에 접근
lastPage = int(pgRR.a["href"].split("=")[-1]) # 마지막페이지 값 추출
이제는 모든 종목별로 데이터를 불러오는 함수를 만들어보자
def getStockPrice(code):
url = 'https://finance.naver.com/item/sise_day.naver?code=' + code #data불러올 웹주소
headers = {'User-agent': 'Mozilla/5.0'} #★★크롤러가 아닌 웹브라우저에서 접속하는 것처럼 보이기 위한정보
req = requests.get(url=url, headers=headers) #get방식을 통해 url에 있는 데이터에 접근
rawData = bs(req.text, 'html.parser')
pgRR = rawData.find('td', class_='pgRR') #마지막 페이지 정보가 있는 항목에 접근
lastPage = int(pgRR.a["href"].split("=")[-1]) #마지막페이지 값 추출
df = pd.DataFrame()
for p in range (1, lastPage+1):
pageUrl = '{}&page={}'.format(url, p) #이렇게 하는 이유는 p가 int인데, pageUrl은 str이라서
pageReq = requests.get(url=pageUrl, headers= headers)
dfFromPage = pd.read_html(pageReq.text)[0]
df = pd.concat([df, dfFromPage])
df = df.rename(columns={'날짜':'date','종가':'close','전일비':'diff'
,'시가':'open','고가':'high','저가':'low','거래량':'volume'}) #영문으로 컬럼명 변경
df['date'] = pd.to_datetime(df['date'])
df = df.dropna()
df[['close', 'diff', 'open', 'high', 'low', 'volume']] = \
df[['close','diff', 'open', 'high', 'low', 'volume']].astype(int) # int형으로 변경
df = df[['date', 'open', 'high', 'low', 'close', 'diff', 'volume']] # 컬럼 순서 정렬
# df = df.sort_values(by = 'date') # 날짜순으로 정렬
return df
마지막으로, 내가 원했던 것은 일자별 종목별 종가만을 모은 dataset이었다.
그래서 종목별로 dataframe에서 종가만 뽑아, 최종적으로 csv파일로 저장해보았다.
codeList = getCodeList() #주식시장 코드 불러오기
#맨처음 파일 생성
rawDf = getStockPrice(codeList[0]) #첫번째 종목 데이터만 크롤링
dfClose = pd.DataFrame({'date': rawDf['date']}) #date이름을 가진 파일 생성
#크롤링 시작!!
for index in codeList:
print("current trial is:{}, {}/{}".format(index, x, len(codeList)) )
rawDf = getStockPrice(index) #크롤링으로 해당 종목에 대한 가격 데이터 df
#serise --> dataframe + dateframe
dfc = pd.DataFrame({'date' : rawDf['date'],"{}".format(index) : rawDf['close']})
dfClose = pd.merge(dfClose, dfc, how = 'outer', on='date')
dfClose.to_csv('NaverCrawling\kospi_closePrice') #저장
x = x + 1성공적으로 잘 작동하는것을 볼수 있었다!
끝.
1. dataframe에서 column선택 --> series 자료형 반환
series = df['column name']
2. series를 dataframe에 붙이기
newDf = pd.Dataframe({'column이름' : series})
3. series --> dataframe으로 바꾸기 + dataframe 열추가
dfA = pd.Dataframe()
dfB = series.to_frame()
newDf = pd.concat([dfA, dfB], ignore_index=true)
df = pd.merge(dfA, dfB)
4. dataframe의 column목록 얻기
columnList = newDf.column
참고사이트
https://sguys99.github.io/trading03
네이버에서 일별 시세 가져오기
네이버에서는 국내 주식과 관련된 다양한 정보를 제공한다. 본 포스트에서는 네이버 금융에서 일별 주식 시세를 가져오는 방법을 소개한다. 1. 홈페이지 둘러보기 네이버 금융에 접속한다. https:
sguys99.github.io
https://yganalyst.github.io/data_handling/Pd_12/
[Pandas 기초] 데이터프레임 합치기(merge, join, concat)
판다스 데이터프레임을 병합하는 여러가지 함수에 대해 알아보자
yganalyst.github.io
https://blog.naver.com/luckymaker77/222599833468
merge & join 함수로 dataframe 병합
dataframe merge - SQL의 join처럼 특정한 column을 기준으로 병합 - join 방식 : how 파라미터를 통해 ...
blog.naver.com
'IT > IT 이것 저것' 카테고리의 다른 글
| (주식 자동 매매) Naver에서 가격 정보 업데이트 자동화_윈도우, anaconda환경(feat, 작업스케쥴러) (0) | 2022.07.27 |
|---|---|
| 비전공자를 위한 IT지식_Json 자료형식이란 (0) | 2022.07.25 |
| 비전공자도 이해하는 클래스(class), 객체(object) 그리고 상속의 개념 (feat. 양념치킨) (0) | 2022.07.18 |
| 클라우드가 미래를 책임진다고? - 그래서 그게 뭔데 (0) | 2020.12.17 |
| (python) investing.com에서 외국 주식 정보 알아보자 (feat. investpy) (0) | 2020.11.26 |
- Total
- Today
- Yesterday
- Unity
- 경영학
- 스타트업
- Anet
- 터틀트레이딩
- 심리학
- 랜덤맵
- 프로그래머스
- 머신러닝
- json
- beautifulsoup
- 마케팅
- 크롤링
- 일자별
- 유니티
- IT기초
- 기초
- 비전공자
- 강화학습
- PYTHON
- ET5X
- It
- 가격데이터
- 주식투자
- 알고리즘
- 주식
- 파이썬
- 시스템투자
- C#
- requests
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |