IT/IT 이것 저것
(python) data crawling (데이터 크롤링) - 누구나 30초만에 기사 제목 크롤링하기
KS짱짱맨
2020. 6. 1. 17:13
오늘 다룰 내용
1. 크롤링을 위한 기본 모듈 및 라이브러리 소개
2. 사이트 접속하기
3. 원하는 데이터 추출하기
오늘 배울 개념
1. HTML 태그와 속성
2. 웹브라우저에서 '개발자 창' 띄우기
2. 세션(Seesion)의 의미
오늘 크롤링해볼 기사는

STEP 1
데이터 크롤링을 위해서 아래와 같이 request 모듈 BeautifulSoup 패키지 등을 불러온다.
import requests
from bs4 import BeautifulSoup
- request = python에서 HTTP요청을 서버로 보내고(request) 그 대답(respnse)을 객체로 받아올 수 있는 모듈
- BeautifulSoup : HTML문서 또는 XML문서에서 특정 내용을 선택하기 위해 사용하는 python 패키지
STEP 2
세션을 만든다.
session = requests.session()- 세션이란, 넓은 의미로 우리가 어떤 '서버에 연결되어있는 동안'를 의미한다.
STEP 3
서버에 요청 및 응답확인 => Get 방식
url = "https://www.yna.co.kr/view/AKR20200601083400002?section=economy/all"
#get방식을 통해 서버에 데이터 요청
response = session.get(url)
# 정상적으로 데이터를 받았는지 확인: <Response [200]> 이면 정상!
print(response)STEP 4
요청된 서버의 내용을
BeautifulSoup을 통해 분석 가능한 객체( 여기서는 'soup' )로 만든다.
soup = BeautifulSoup(response.text,'html.parser')
STEP 5
필요한 데이터의 HTML태그와 속성을 살펴본다.
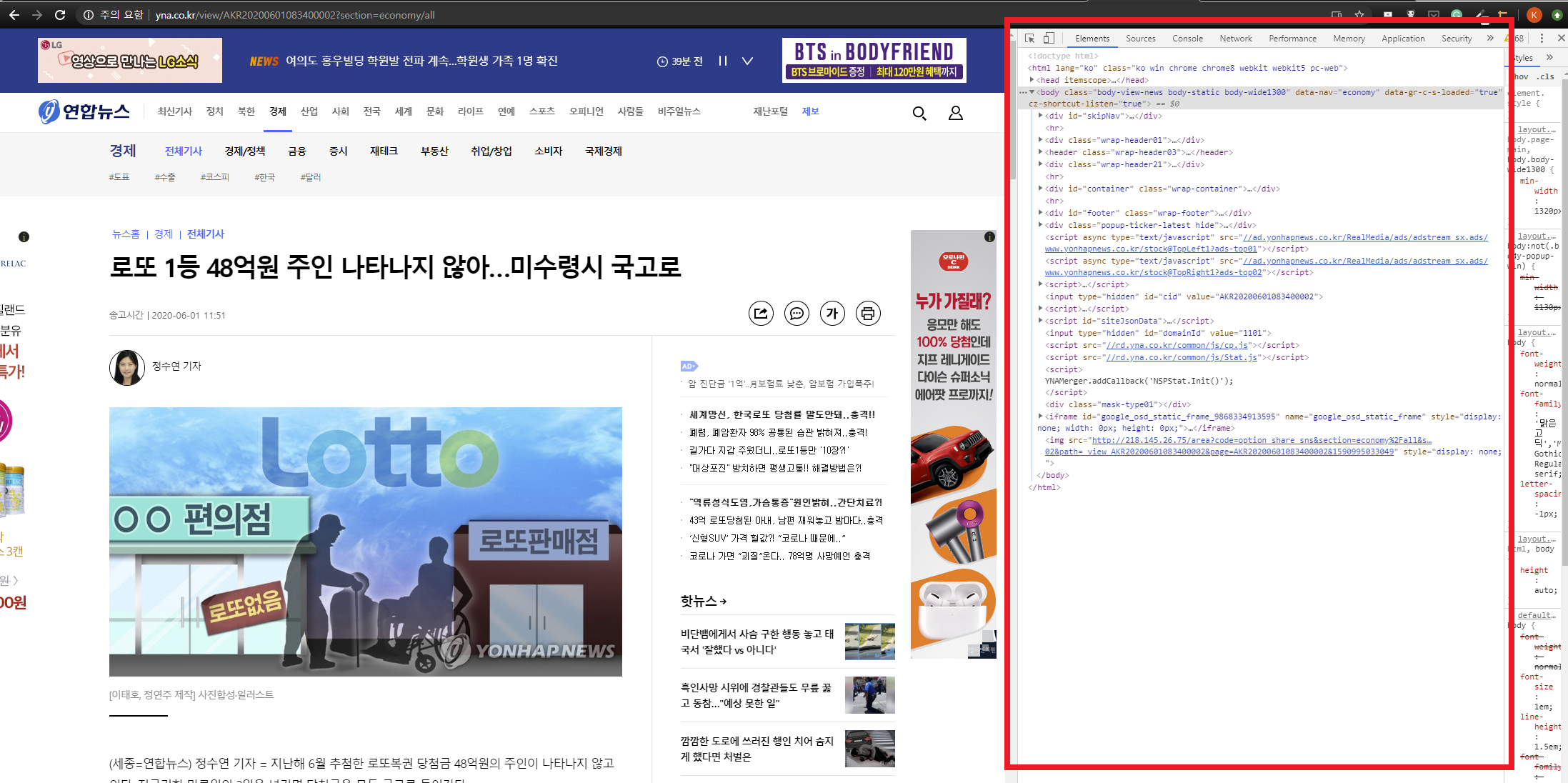


- 여기서 보라색 글자(h1)인 것이 Tag이고,
- class = "tit" 이라고 적힌것이 속성이다.
STEP 6
태그와 속성을 활용하여 제목을 불러와 제목의 text만 불러온다.
title = soup.select_one("h1.tit").text
print(title)
# 로또 1등 48억원 주인 나타나지 않아…미수령시 국고로
끝.
참고싸이트
https://blog.naver.com/studyseony/222675450238
#2 웹 크롤링 BeautifulSoup 라이브러리
BeautifulSoup 라이브러리 : 응답데이터를 파이썬 객체로 변환한 후에 원하는 데이터를 추출 · bs(변환할...
blog.naver.com
728x90